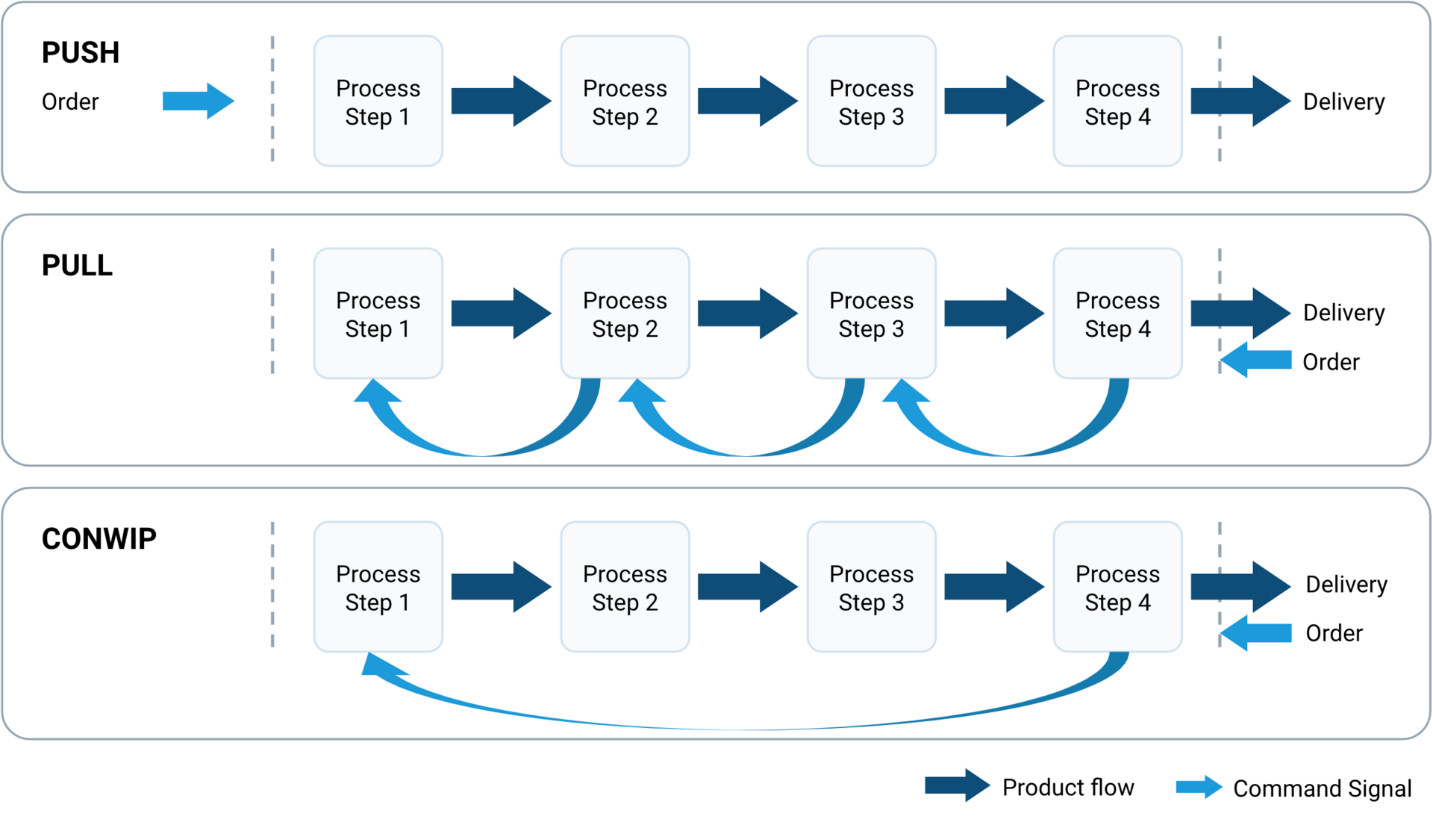
数据推拉模型(Push-Pull Model)
摘要:数据推拉模型是一种描述数据在系统组件之间传输方式的架构模式,定义了数据生产者(源)与数据消费者(目标)之间的交互机制。 免费下载软件
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。
简介
数据推拉模型是一种描述数据在系统组件之间传输方式的架构模式,定义了数据生产者(源)与数据消费者(目标)之间的交互机制。在推模式(Push)中,数据源主动将数据发送到目标端;在拉模式(Pull)中,数据消费者主动从源端请求或获取数据。实际系统中往往采用混合模式,即数据推拉模型,根据业务需求、网络条件、实时性要求和系统负载,动态或静态地组合两种传输方式,以优化数据流的效率、可靠性和资源利用率。该模型广泛应用于消息队列系统、数据同步机制、流处理平台和分布式缓存等场景。
适用场景
数据推拉模型广泛应用于需要在不同系统组件间高效传输数据的各类架构中。在消息队列系统中,生产者推送到队列,消费者从队列拉取处理,实现解耦和削峰填谷;在数据同步场景中,源系统推送变更数据,目标系统定期拉取全量数据进行校对;在流处理平台中,数据源持续推送实时流,处理引擎按需拉取批数据进行窗口计算;在分布式缓存系统中,缓存节点主动推送失效通知,应用服务器根据需要拉取最新数据;在物联网环境中,传感器设备推送实时监测数据,中央控制系统按需拉取历史数据进行趋势分析。该模型特别适合需要平衡实时性与系统负载、处理能力不对等、或网络条件不稳定的分布式系统。
优点:数据推拉模型的最大优势在于其高度的灵活性和资源优化能力。通过推模式保障高实时性场景下的数据快速到达,同时借助拉模式避免目标端持续轮询的开销或源端过载推送的风险,两者结合可实现精细化的系统负载管理。该模型强化了生产者和消费者之间的解耦,允许双方独立扩展和维护,无需感知对方的具体状态。在容错方面,拉模式支持消费者断点续传,推模式可配合确认机制确保数据可靠送达,显著提升分布式系统的鲁棒性。此外,推拉混合设计能够适配异构环境——无论是处理能力不等的节点、波动的网络带宽,还是动态变化的业务负载,都能在复杂条件下维持数据传输的稳定性和效率。
缺点: 数据推拉模型的主要挑战源于其架构复杂性带来的系统性风险。同时实现推和拉两种机制需要设计复杂的协调逻辑、状态管理和模式切换策略,显著增加开发和运维成本。在数据一致性方面,混合模式容易引发数据到达顺序错乱、重复处理或时序冲突等问题,必须引入版本控制、幂等性设计等额外机制来保障正确性。延迟特征的不确定性也是突出问题——拉模式引入轮询间隔导致的固有延迟,叠加推模式在网络拥塞时可能产生的积压,使得端到端的延迟难以预测和优化。此外,模式选择、状态同步和流量控制所需的额外通信开销可能在高频交互场景中成为性能瓶颈,而多样化的数据流动路径更让问题定位和异常排查变得异常困难,特别是在跨多个组件的推拉混合链路中追踪数据丢失或重复异常时尤为突出。
图例
1. 数据推拉模型。
2. 数据推拉策略。