反爬虫机制(Anti-Scrapingtechniques)
反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。
2023-10-20 10:28:18
反爬虫机制(Anti-scrapingtechniques)是一种用于保护网站和在线数据资源免受自动化爬虫程序(通常是爬虫机器人或爬虫软件)侵害的技术和方法。这些机制的目的是确保网站的合法用户能够正常访问和使用网站,同时限制或阻止未经授权的数据采集,以保护隐私、数据安全和网络性能。
2023-10-20 10:28:18
网络爬虫,也称为Web爬虫或网络蜘蛛,是一种自动化的程序或脚本,被设计用来浏览互联网,以收集信息、数据或执行特定任务。这些任务可以包括搜索引擎索引、数据挖掘、价格比较、内容抓取、自动化测试等等。
2023-10-24 16:06:06
爬取频率是指网络爬虫或爬虫程序从目标网站上获取数据的时间间隔或频繁程度。
2023-10-24 14:24:57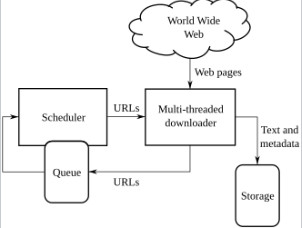
垂直爬虫(Vertical Crawling)是一种针对特定领域、行业或主题进行数据采集的网络爬虫技术。与覆盖所有类型网页的通用搜索引擎不同,垂直爬虫专注于某一特定垂直领域,例如电子商务、招聘信息、房地产、新闻或学术论文等。它通过预先定义的网站列表、结构化解析规则以及行业领域知识,精准提取关键数据,从而为特定应用场景构建高质量的结构化数据集。
2026-04-28 15:28:06
数据抓取,也被称为网络爬虫、网页抓取、数据挖掘或网络数据采集,是指自动从互联网或计算机网络上提取信息、数据和内容的过程。这个过程通常通过编写计算机程序来实现,这些程序被称为爬虫或抓取器。
2023-10-23 10:55:14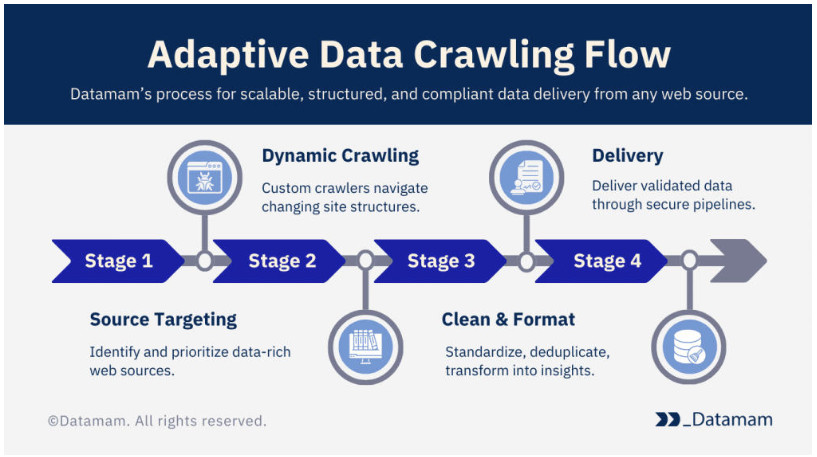
自适应采集策略(Adaptive Crawling Strategy)是一种在网页爬虫或数据收集系统中,通过动态评估目标网站的更新频率、重要性、响应状态、资源限制等因素,灵活调整爬取对象、频率和优先级的爬取方法。
2025-12-24 01:57:00
后羿采集器一款真正免费的爬虫软件,针对采集数据所需要的基础功能,没有任何限制,不需要积分。
2018-08-20 15:53:10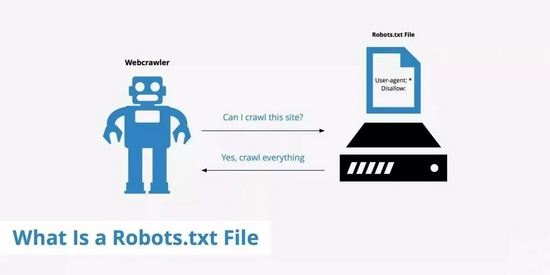
Robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个Robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。
2023-10-24 15:03:49
网页抓取是指从互联网上获取信息或数据的过程,通常通过自动化的程序来执行。这些程序被称为网络爬虫或网络机器人,它们浏览网页、提取信息并将其存储或进一步处理。
2023-10-24 14:39:07
网页快照采集(Web Snapshot Collection) 是指利用网络爬虫或自动化工具,在某一特定时间点对网页内容进行完整捕获、存储与归档的技术过程。与传统的文本或结构化数据采集不同,网页快照采集更强调保留网页在某一时刻的原始呈现状态,包括 HTML 结构、层叠样式表(CSS)、JavaScript 脚本、图片、视频及其他多媒体资源,以及页面布局信息和部分交互状态。通过这种方式,可以将网页内容“冻结”为静态副本,从而记录网页在历史时间节点的真实状态,为信息保存、证据留存、内容对比以及数字档案研究提供基础支撑。
2026-04-28 15:23:45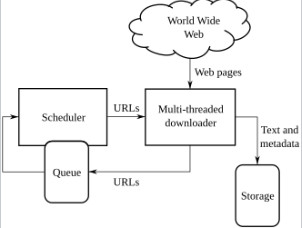
Deep Crawling refers to a technical method in which a web crawler not only collects information from the homepage or surface pages of a target website but also recursively follows links within pages to continuously access and collect data from deeper levels of the site. Unlike shallow crawling, which only captures surface-level pages, deep crawling can penetrate a website's directory structure, pagination navigation, category links, and dynamically loaded content, thereby obtaining more comprehensive and complete data resources. This technique typically requires the integration of link deduplication, crawling strategy optimization, anti-scraping mechanism handling, and distributed scheduling to efficiently and stably complete large-scale data collection tasks.
2026-03-23 07:05:00
数据加密(Data Encryption)是一种通过加密算法和加密密钥将明文(原始数据)转换为密文(加密后的数据)的过程,而解密则是通过解密算法和解密密钥将密文恢复为明文的过程。
2024-09-26 20:20:40