垂直爬取(Vertical Crawling)
摘要:垂直爬虫(Vertical Crawling)是一种针对特定领域、行业或主题进行数据采集的网络爬虫技术。与覆盖所有类型网页的通用搜索引擎不同,垂直爬虫专注于某一特定垂直领域,例如电子商务、招聘信息、房地产、新闻或学术论文等。它通过预先定义的网站列表、结构化解析规则以及行业领域知识,精准提取关键数据,从而为特定应用场景构建高质量的结构化数据集。 免费下载软件
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。
简介
垂直爬虫(Vertical Crawling)是一种针对特定领域、行业或主题进行数据采集的网络爬虫技术。与覆盖所有类型网页的通用搜索引擎不同,垂直爬虫专注于某一特定垂直领域,例如电子商务、招聘信息、房地产、新闻或学术论文等。它通过预先定义的网站列表、结构化解析规则以及行业领域知识,精准提取关键数据,从而为特定应用场景构建高质量的结构化数据集。
适用场景
垂直爬虫广泛应用于行业数据分析、价格监测、人才招聘、房地产市场研究、学术文献聚合以及新闻情感分析等领域。在电子商务领域,它可以抓取商品价格、销量和用户评价,用于竞争分析和市场监测;在招聘领域,它可以收集职位发布信息和薪资数据,用于分析劳动力市场趋势;在房地产领域,它可以采集房源信息及价格变化,为投资研究提供数据支持;在学术领域,它可以提取论文元数据和引用关系,用于构建知识图谱。
优点:垂直爬虫的核心优势在于数据采集的精准性以及结构化数据输出能力。通过专注于特定领域,爬虫可以针对特定网页模板设计精细的解析规则,从而提取格式统一、结构清晰的数据,大幅降低后续数据清洗成本。与通用爬虫相比,垂直爬虫通常资源消耗更低,并且更容易根据业务需求进行定制。此外,它还能够获取许多通用搜索引擎难以触及的深层行业数据。
缺点:当目标网站进行页面改版或更新反爬机制时,垂直爬虫容易面临稳定性问题。由于解析规则通常依赖特定的页面结构,一旦页面模板发生变化,就可能导致数据提取失败,因此需要频繁维护。此外,每个目标网站通常需要单独配置解析规则,随着采集规模扩大,维护成本也会不断增加。现代网站中大量使用的动态加载、异步请求以及反爬措施(如IP封禁、验证码等)也增加了技术实现的复杂度。最后,数据采集活动还必须遵守网站服务条款以及相关法律法规,以避免合规风险。
图例
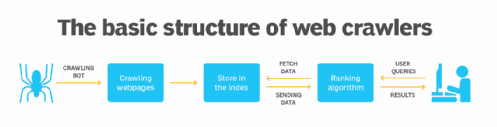
1. 标准 Web 爬虫的高级架构。
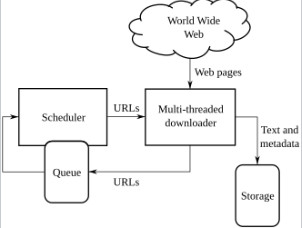
2. Web 爬虫的基本结构。