【智能模式】【流程图模式】如何实现断点续采
摘要:本教程为大家介绍如何实现断点续采功能 免费下载软件
在采集的过程中,我们可能会遇到异常停止的情况,如果我们希望再一次启动任务时从上一次停止的位置开始采集,我们需要使用断点续采的功能。
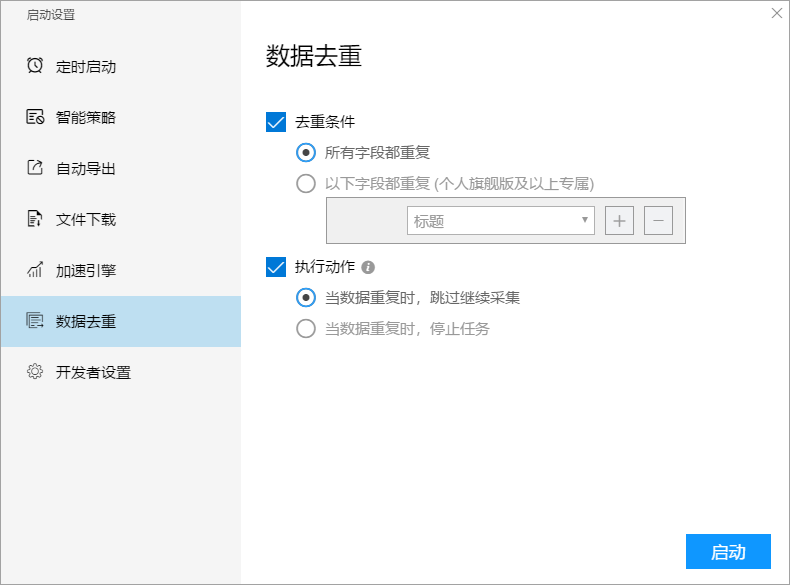
1、通过去重功能来进行断点续采
直接在启动任务时进行数据去重设置,选择“当所有字段都重复时,跳过继续采集”。
该方案设置简单,但是效率较低,设置之后任务仍然会从第一页开始采集,然后逐个跳过所有已经采集到的数据。
2、通过修改采集范围、修改网址或添加预操作来进行断点续采
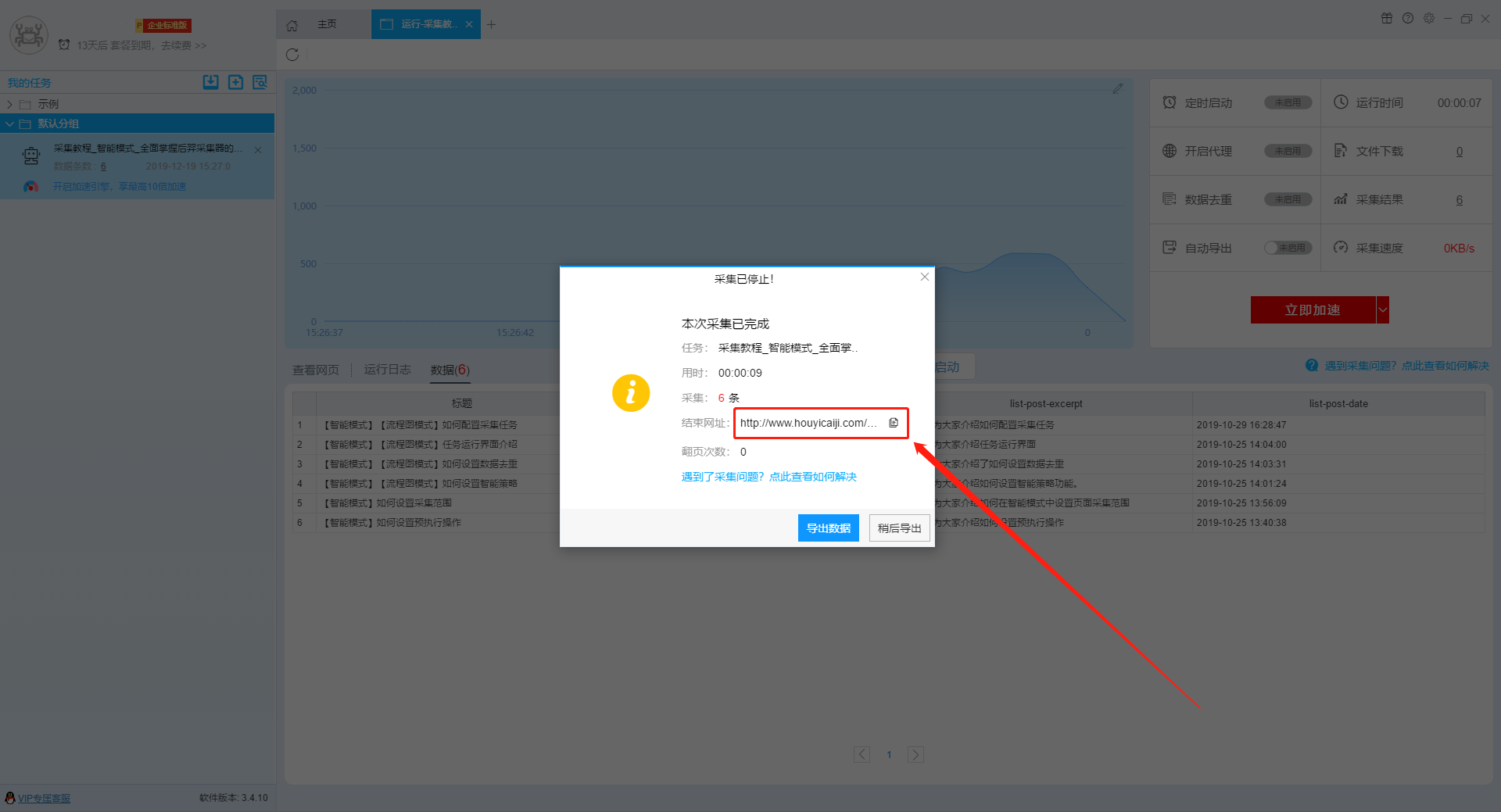
当任务停止时,软件的停止界面上会记录当前任务采集到最后一条时的网址和翻页次数,一般情况下,停止网址是准确的,但是翻页次数可能会大于真实的数值,因为如果发生页面卡住的情况会有空翻页的次数。
大家可以使用这两个数值作为断点续采的参考依据。
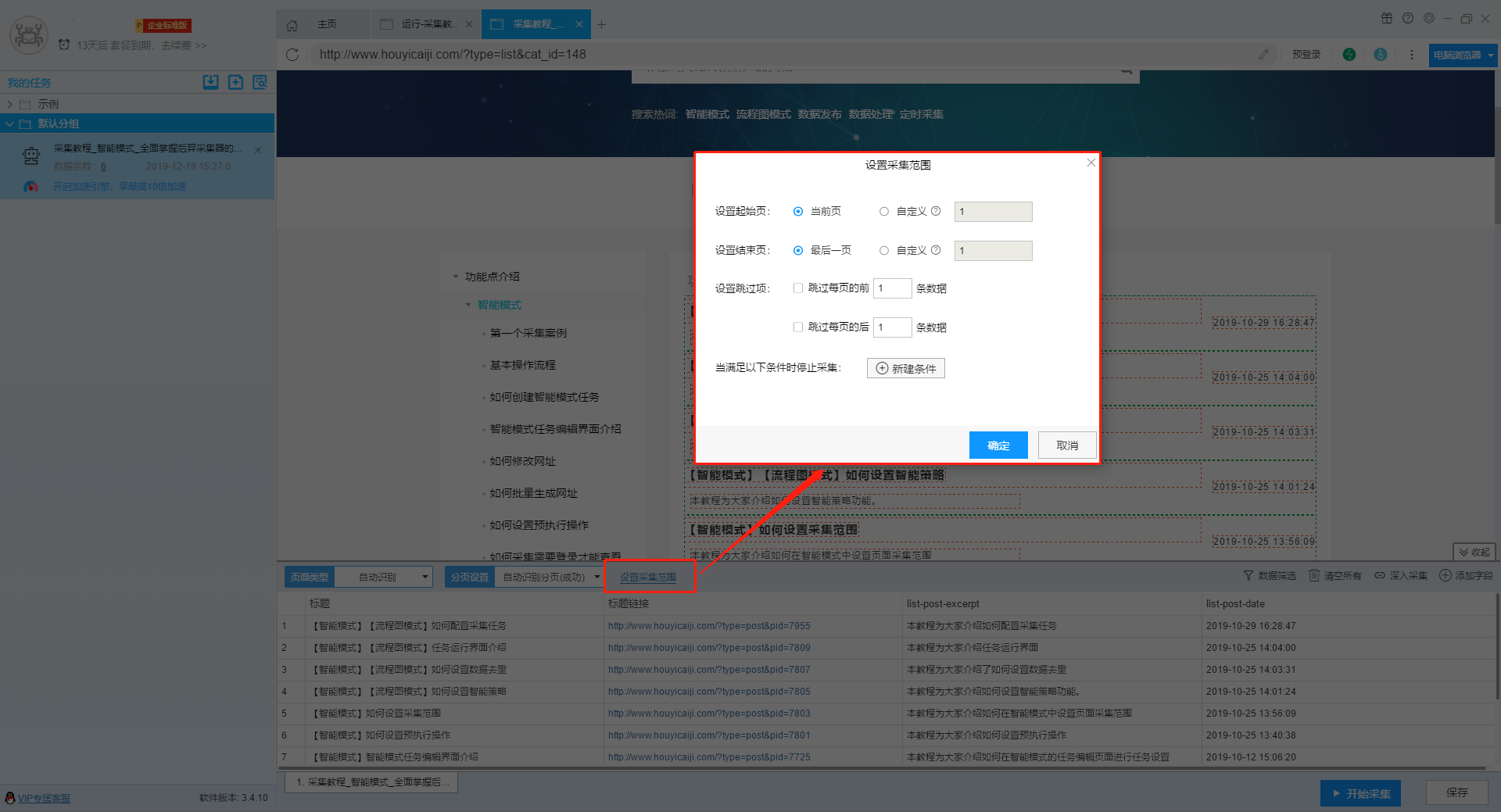
1)修改采集范围(适用于智能模式)
第一步:复制采集停止的网址,参考翻页次数,找到准确的翻页次数
第二步:智能模式中直接设置采集范围的起始页数值为第一步中的翻页次数
2)修改网址或添加预操作
一般可以可以分为以下几种情况:
I、网址会随着页码的变动而变动的网站(适用于智能模式或流程图模式)
如这种:
http://www.houyicaiji.com/?type=list&cat_id=148&page=1
http://www.houyicaiji.com/?type=list&cat_id=148&page=2
http://www.houyicaiji.com/?type=list&cat_id=148&page=3
http://www.houyicaiji.com/?type=list&cat_id=148&page=…..
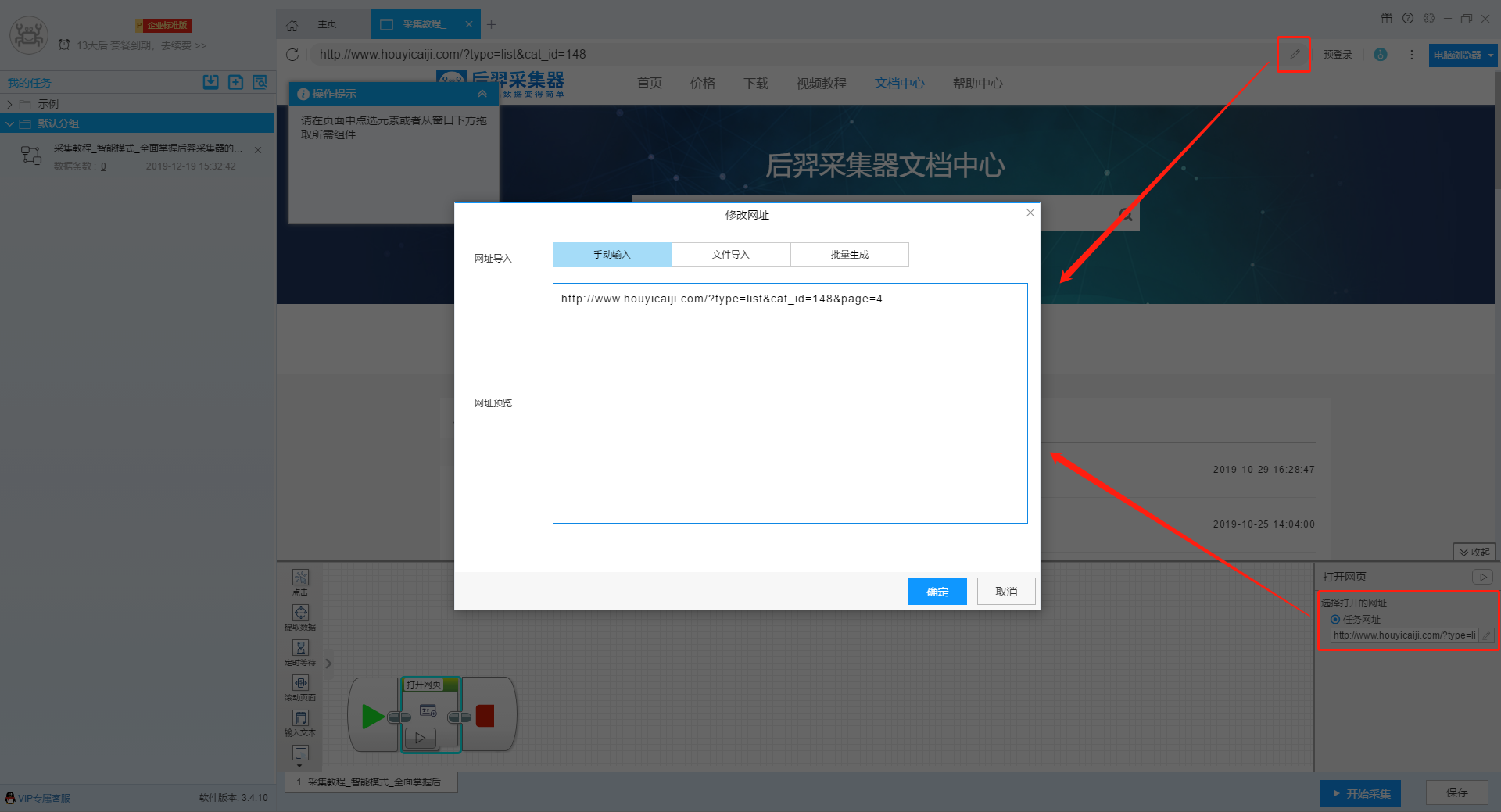
这种情况下假设我们采集到第4页时断掉了,我们可以直接复制第4页的网址,然后在原任务中修改网址,然后重新采集。
【温馨提示】如果之前采集到的数据需要保留则不要点击清空数据。
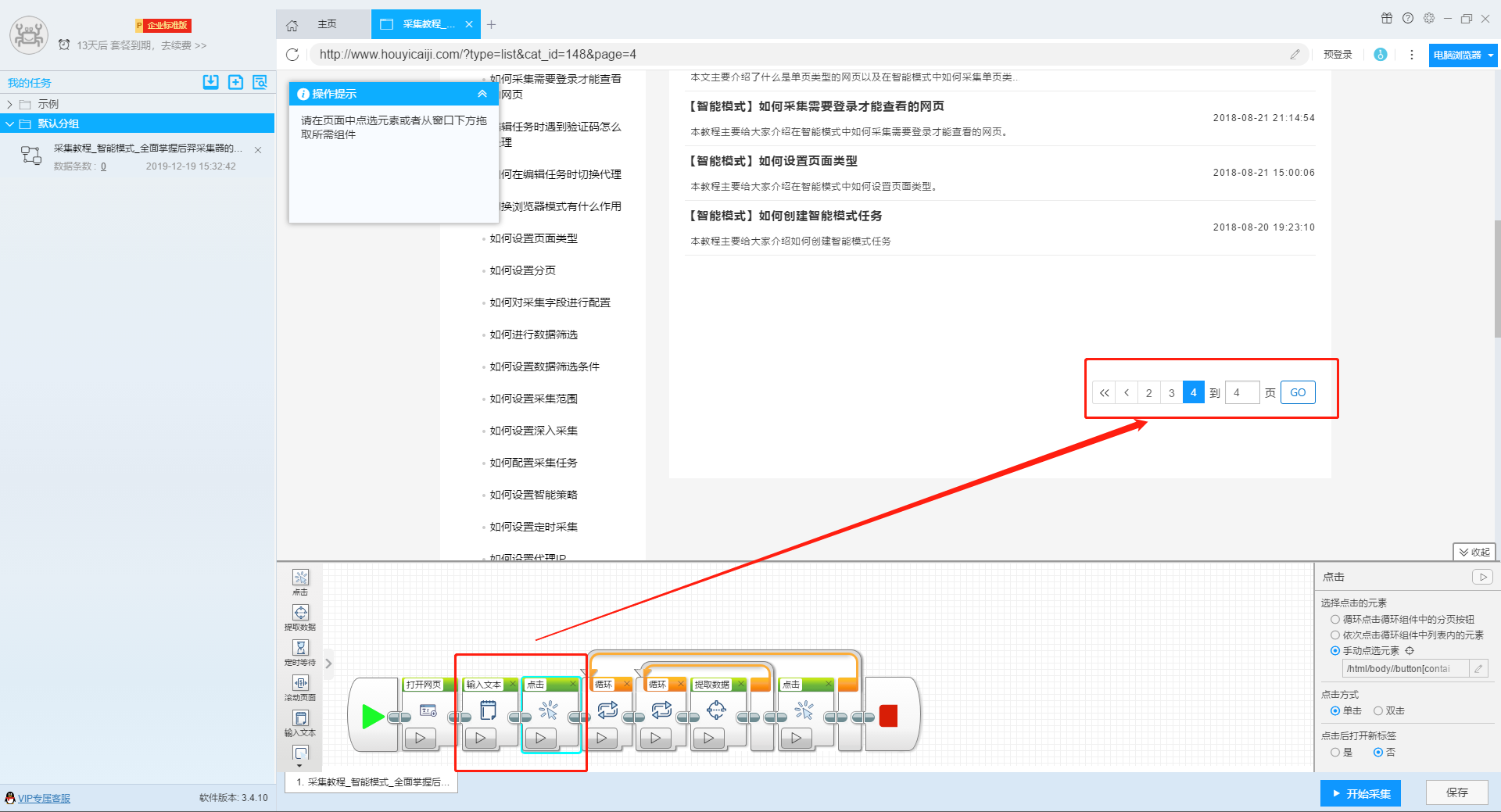
II、网址不会随着页码的变动而变动的网站(适用于流程图模式)
如果该网站,无论页数怎么变动,网址也不会变动的情况下,我们点击页面上的分页按钮,在操作提示框内选择点击“循环点击该元素”按钮,此时软件上会设置一个新的翻页循环按钮。
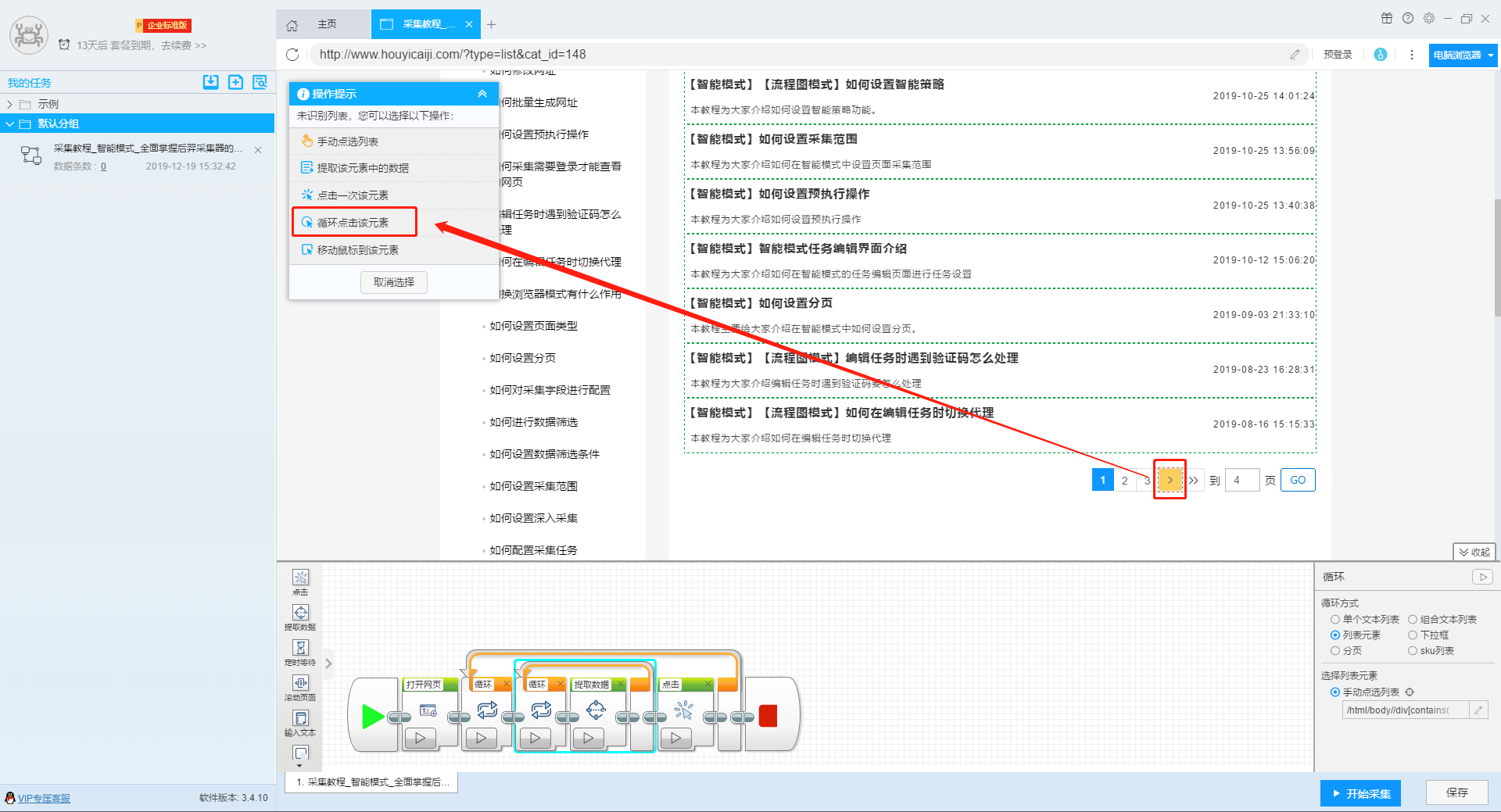
假设之前的任务在第3页停止,用户要从第4页开始采集,则可以在这个翻页循环上设置自定义翻页次数“3”。
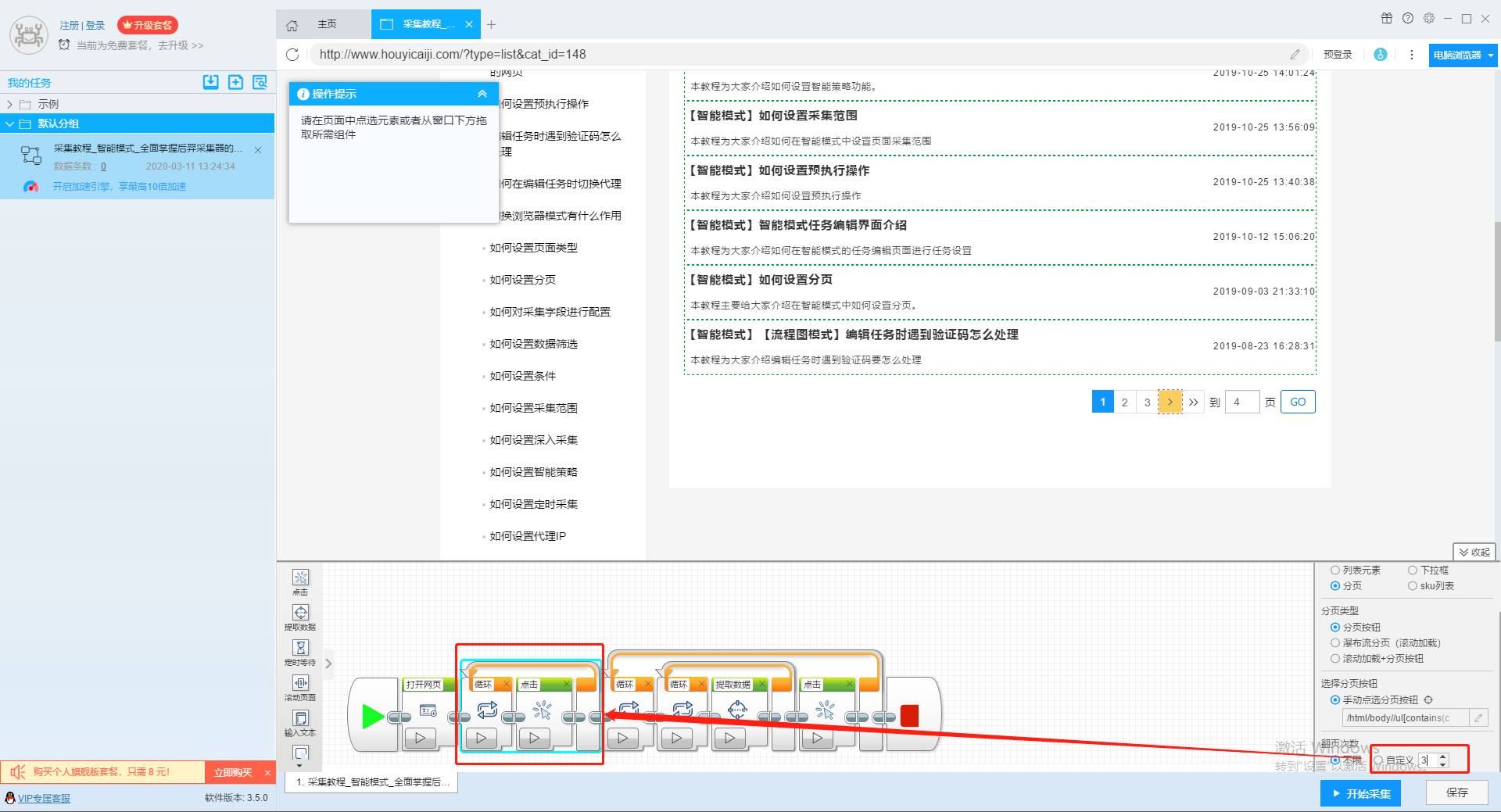
III、网址不会随着页码的变动而变动,但是页码可以通过输入的方式直接跳转的网站(适用于智能模式或流程图模式)
有一些网站的网址虽然不会随着页码的变动而变动,但是页码部分有输入框,可以直接输入页数跳转到相应的页码,如以下这种网站:
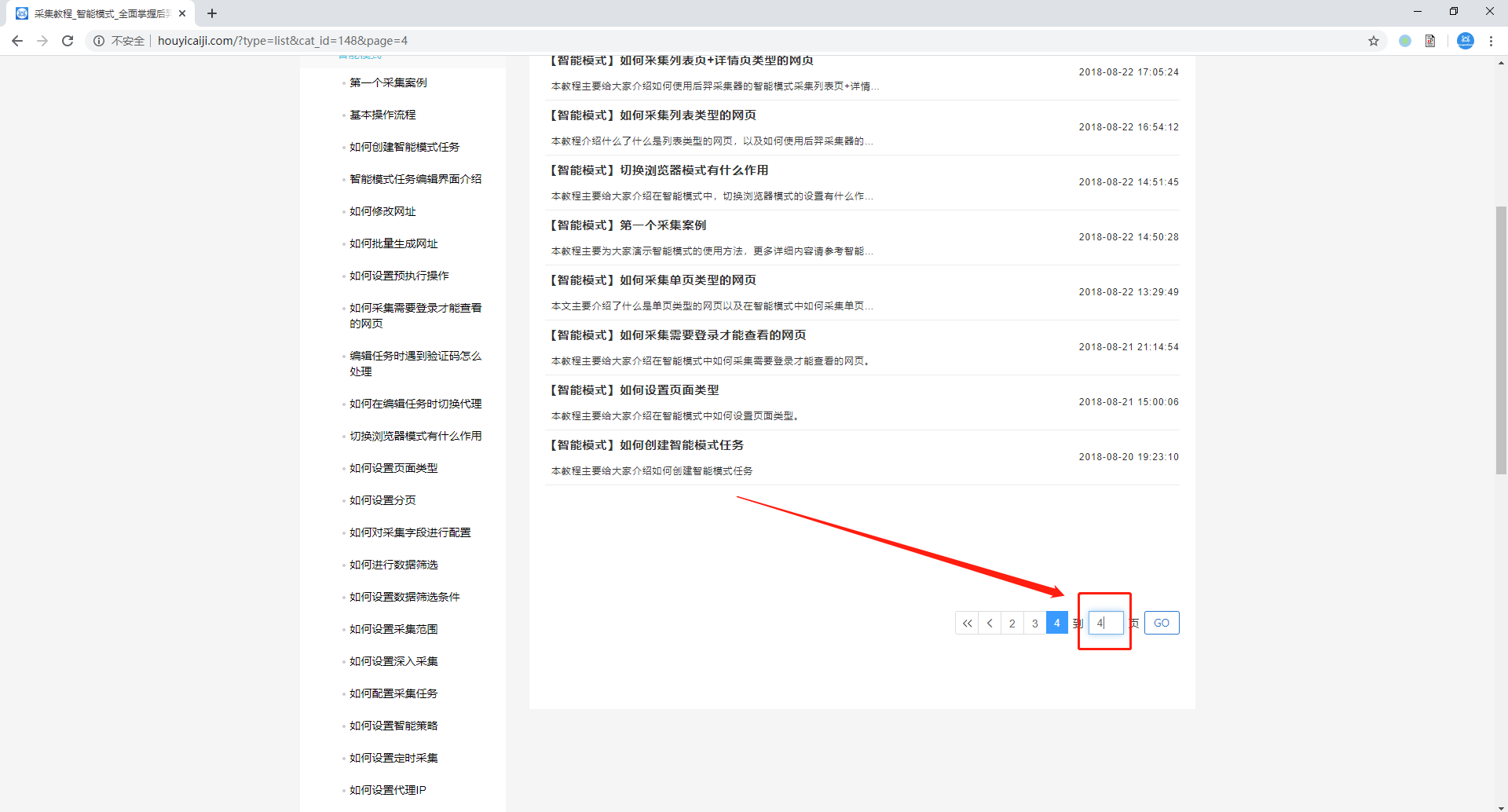
针对这种网站,我们点击页面上的输入框,在跳转出的操作提示框内输入想要跳转的界面,此处用第4页来举例,在输入框内填入数字“4”之后,点击确定,软件上会出现一个输入文字组件。
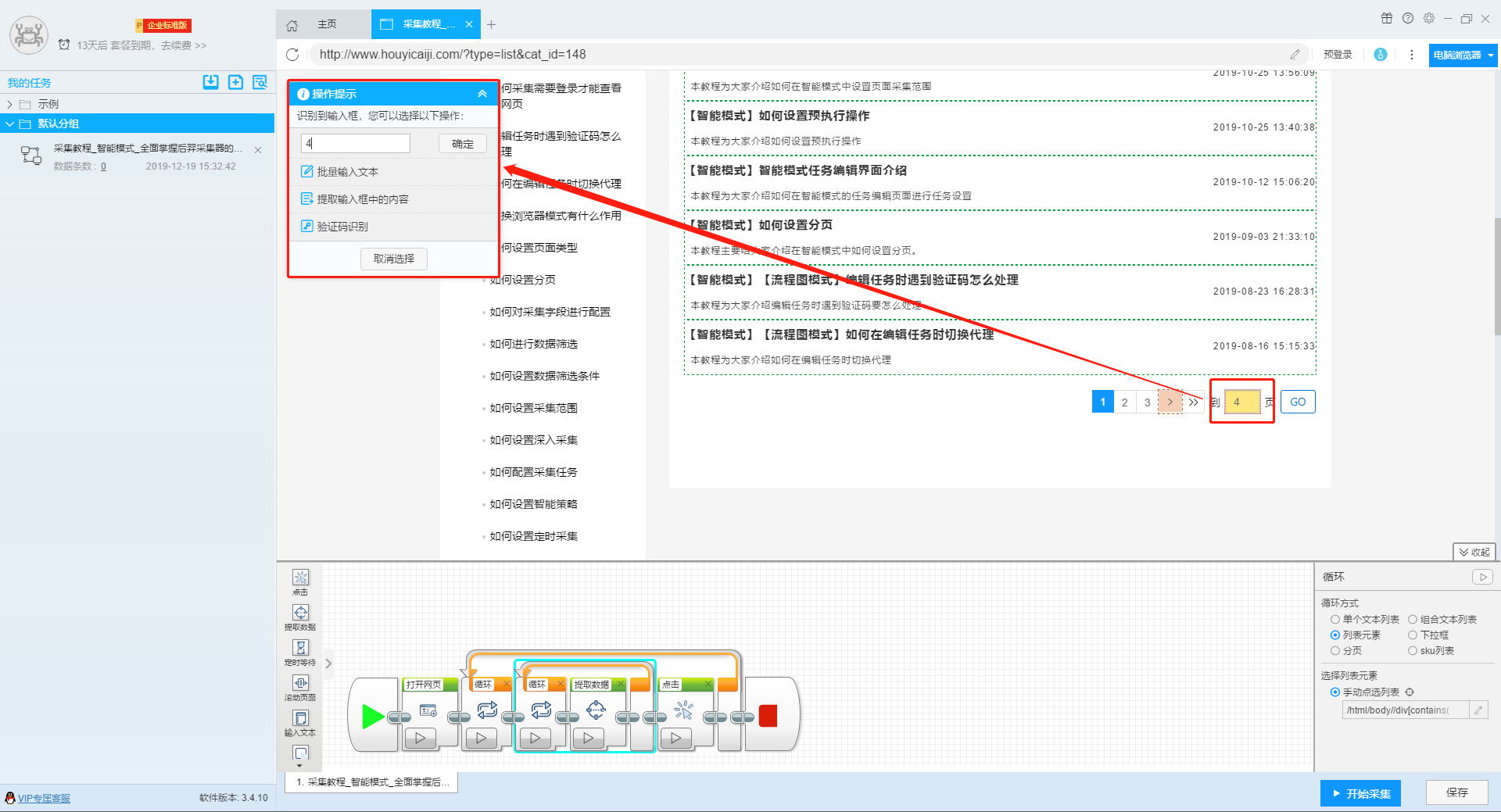
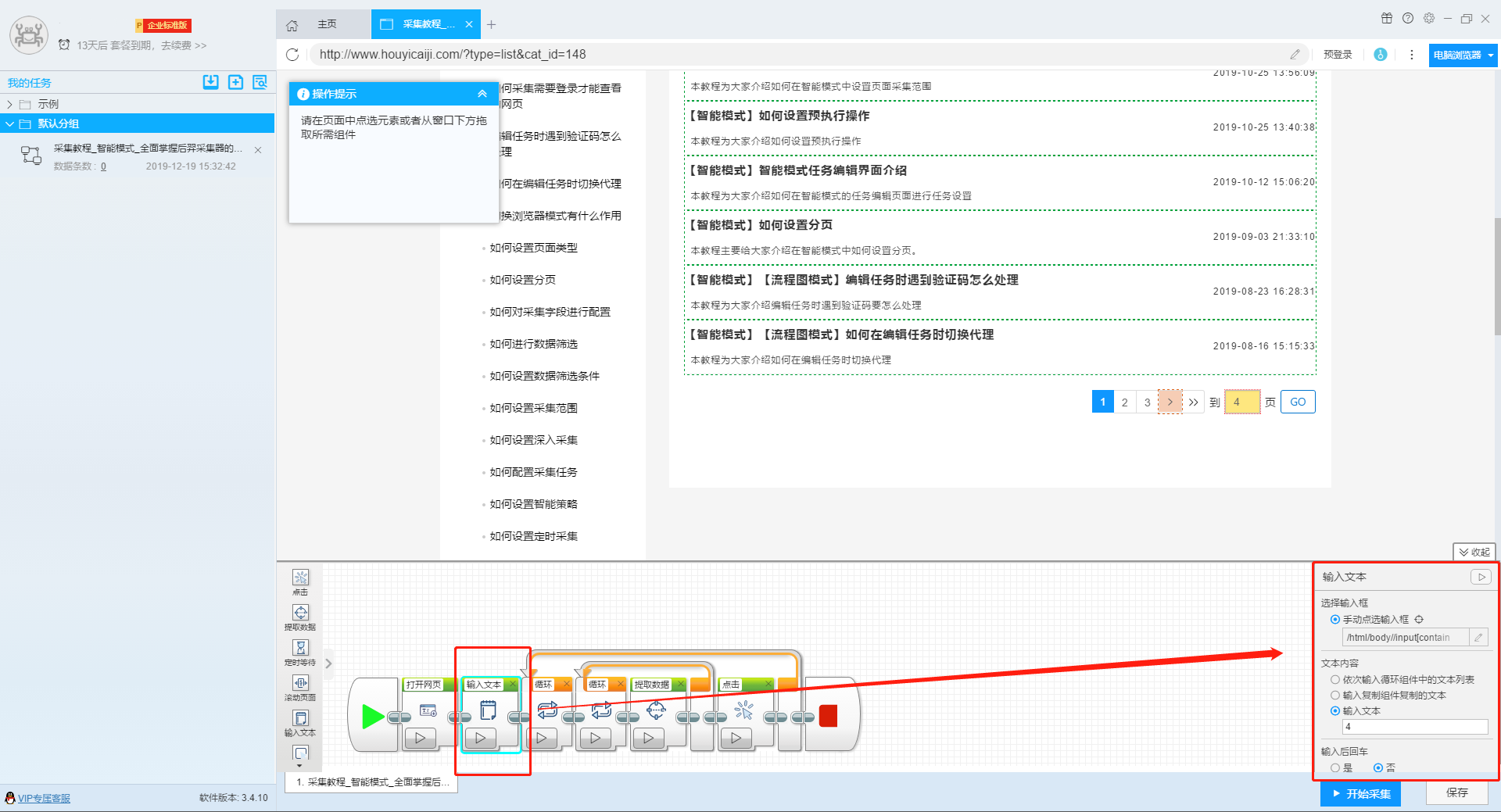
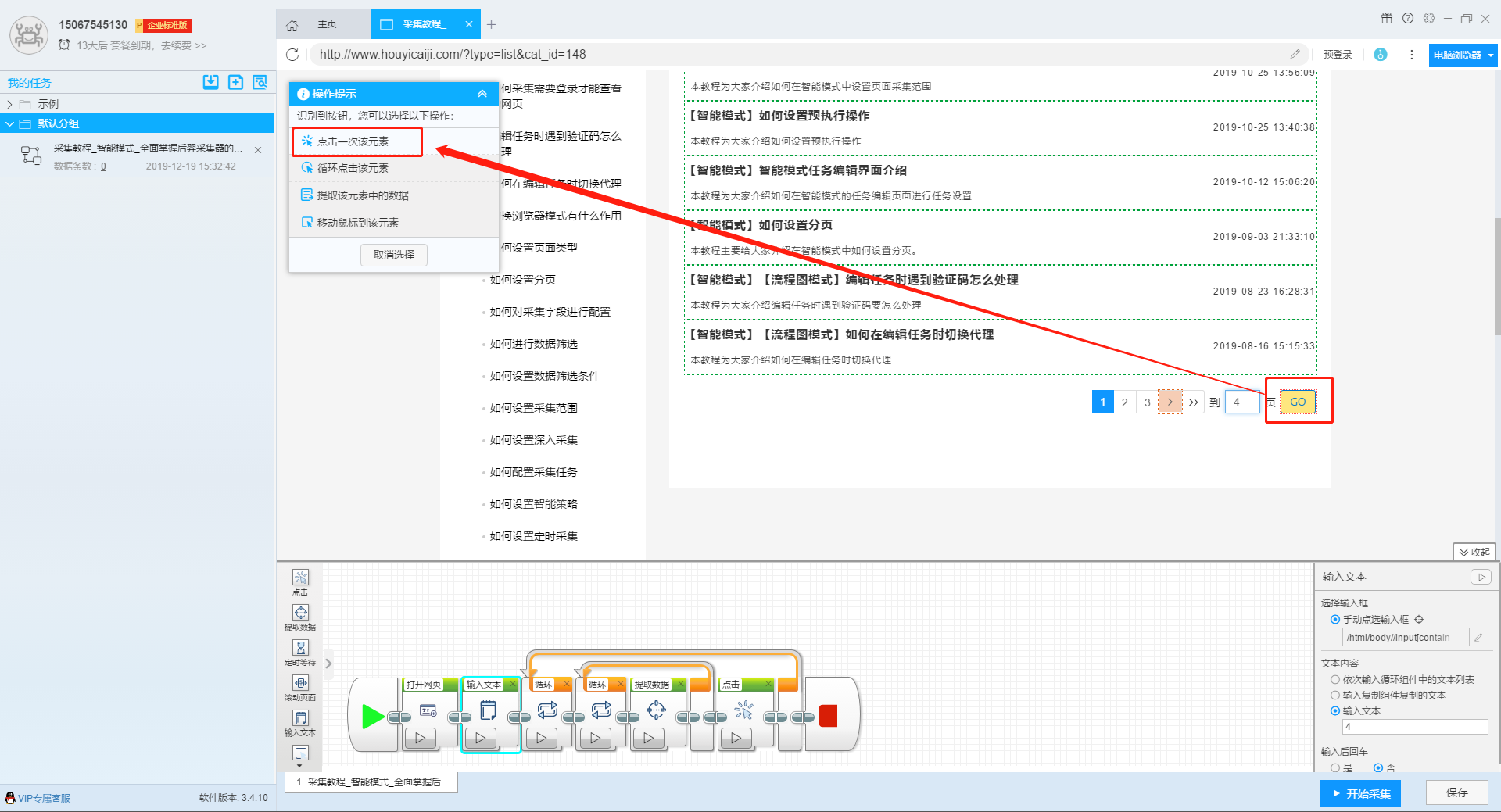
我们再点击页面上“go”按钮,在跳转出来的提示操作框上选择“点击一次该元素”按钮,页面就会跳转到第4页去了。
补充:
我们可以在采集任务中增加特殊字段来记录采集状态,包括起始网址(创建任务时输入的网址)、数据ID、当前页码、当页排名和当前网页URL。
设置方法如下:
第一步:添加字段
第二步:右击该字段,在菜单中选择“改为特殊字段”
这个数据直接反应在采集结果中,所以会更加准确。