自适应采集策略(Adaptive Crawling Strategy)
摘要:自适应采集策略(Adaptive Crawling Strategy)是一种在网页爬虫或数据收集系统中,通过动态评估目标网站的更新频率、重要性、响应状态、资源限制等因素,灵活调整爬取对象、频率和优先级的爬取方法。 免费下载软件
后羿采集器,基于人工智能技术,无需编程,可视化操作,免费导出采集结果,只需输入网址就能自动识别采集内容的数据采集工具。
简介
自适应采集策略(Adaptive Crawling Strategy)是一种在网页爬虫或数据收集系统中,通过动态评估目标网站的更新频率、重要性、响应状态、资源限制等因素,灵活调整爬取对象、频率和优先级的爬取方法。与传统固定时间表型爬取不同,该策略将实际数据更新情况和系统负载作为反馈,旨在维持效率与全面性的最佳平衡。它在搜索引擎、数据聚合平台、监控系统等需要大规模且持续信息收集的领域发挥着重要作用。
适用场景
适用于收集大量更新频率差异显著的网站或API数据的环境,例如搜索引擎索引更新、新闻或电商网站的价格与库存监控、社交媒体分析、开放数据定期收集、竞争对手信息追踪等。尤其在网络带宽或计算资源有限、需优先获取高价值信息的系统中效果显著。
优点:可根据页面更新频率和历史爬取结果自动调整爬取间隔,减少不必要的重复获取,从而高效利用带宽和计算资源。同时,它支持基于重要性和时效性的优先级排序,可快速收集高价值信息。此外,该策略能检测故障或响应延迟并调整行为,有助于减轻目标网站负载并提升系统整体稳定性。
缺点:策略设计较为复杂,需要高度专业知识来设计并优化用于更新频率预测和重要性评估的算法。在初期阶段,由于缺乏足够的历史数据,可能难以做出最优爬取决策。此外,若使用错误的评估指标,可能导致重要页面遗漏或爬取过度集中于特定内容的风险。
图例
1. 适应性数据爬取流程图。
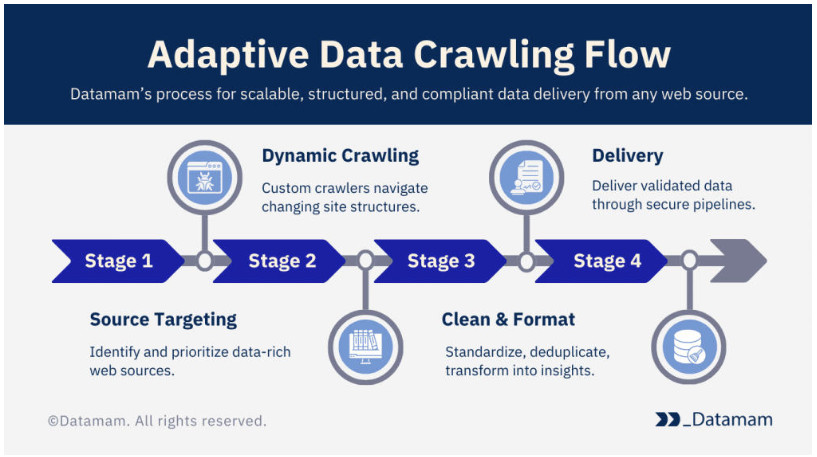
2. 适应性数据爬取流程图。